

In dit artikel leggen we uit hoe het proces van crawlen en indexeren werkt en waarom het belangrijk is voor SEO of zoekmachine optimalisatie.
Wat is crawlen?
Zoekmachines doorzoeken continu het internet, op zoek naar relevante content. Dat doorzoeken van websites noemen we crawlen. Crawlers of bots verkennen websites om hun inhoud vervolgens te indexeren. Ze springen hierbij van link naar link.
Omdat er dagelijks duizenden nieuwe webpagina’s worden aangemaakt, is het crawlen een mechanisme dat nooit stopt en zich keer op keer herhaalt.
Martin Splitt, Google Webmaster Trend Analyst, omschrijft het als volgt:
“We start somewhere with some URLs, and then basically follow links from thereon. So we are basically crawling our way through the internet (one) page by page, more or less.”
Martin Splitt
Crawlen is de eerste stap in het proces om in de zoekresultaten te verschijnen. De andere stappen zijn indexeren en ranken, om dan uiteindelijk je pagina in de zoekresultaten te tonen.
Wat is een zoekmachine crawler?
Een zoekmachine crawler, ook wel eens een spider of een crawl bot genoemd, is een stukje software dat webpagina’s doorzoekt (crawlt), het scant de content en verzamelt data voor indexatie doeleinden.
Telkens wanneer een crawler een nieuwe pagina bezoekt via een hyperlink, kijkt hij naar de inhoud van die pagina – hij scant alle tekst, afbeeldingen, links, HTML, CSS of JavaScript bestanden enz. – en geeft vervolgens deze informatie door voor verwerking en indexering.
Zoekmachine Google gebruikt vooral deze twee crawlers om webpagina’s te crawlen:
- GoogleBot Smartphone – primaire crawler
- GoogleBot Desktop – secundaire crawler
Gezien de mobile first policy van Google, zal GoogleBot bij voorkeur steeds eerst de mobiele versie van een website crawlen. Daarna is het goed mogelijk dat ook de secundaire crawler je website scant om afwijkende content te detecteren van de mobiele versie.
De crawlfrequentie van nieuwe pagina’s wordt bepaald door het crawlbudget.
Wat is crawlbudget?
Het crawlbudget bepaalt hoeveel en met welke frequentie crawlers je website bezoeken. Met andere woorden: het crawlbudget bepaalt hoeveel pagina’s er worden gecrawld en hoe vaak die pagina’s opnieuw worden gecrawld, door bijvoorbeeld GoogleBot.
Het crawlbudget wordt vooral beïnvloed door deze twee zaken:
- Crawl rate limiet: het aantal pagina’s die tegelijkertijd op een website kunnen worden gecrawld zonder de server te overbelasten.
- Crawl demand: het aantal pagina’s dat moet gecrawld en / of hercrawld worden.
Het crawlbudget is vooral belangrijk voor grote websites met miljoenen pagina’s, niet voor kleine websites met slechts enkele tientallen pagina’s. Rekening houden met crawlbudget is daarom cruciaal voor de e-commerce SEO strategie van grote webshops.
Wat is indexeren?
Indexeren is het proces van analyseren, inventariseren en opslaan van content van de gecrawlde webpagina’s in een database (ook wel de index genoemd). Enkel geïndexeerde pagina’s kunnen opgenomen worden in de zoekresultaten.
Telkens wanneer een zoekmachine crawler een nieuwe pagina ontdekt, zal deze content in de indexering terecht komen. Daar wordt de content geparseerd zodat de inhoud beter begrepen wordt en vervolgens opgeslagen in de index.
Martin Splitt legt uit wat de indexering precies doet:
“Once we have these pages (…) we need to understand them. We need to figure out what is this content about and what purpose does it serve. So then that’s the second stage, which is indexing.”
Google maakt hiervoor gebruik van het Caffeine Indexing System dat in 2010 werd geïntroduceerd.
De database van de Caffeine Index kan miljoenen gigabytes aan webpagina’s bevatten. Deze pagina’s worden systematisch verwerkt en geïndexeerd (en opnieuw gecrawld) door de GoogleBot op basis van de content die ze bevatten.
Zoals eerder al aangehaald, bezoekt GoogleBot liever eerst de website met de mobiele crawler sinds de zogenaamde Mobile-First Indexing update.
Wat is Mobile-First Indexing?
Mobile-First Indexing werd geïntroduceerd in 2016 toen Google aankondigde dat het in eerste instantie content gingen indexeren en gebruiken die beschikbaar was op de mobiele versie van websites.
De officiële verklaring van Google is duidelijk:
Het is logisch dat Google eerst naar mobiele websites kijkt aangezien mensen tegenwoordig veel meer hun mobiele telefoons gebruiken om het internet te raadplegen.
Opmerking: het is belangrijk om te beseffen dat Mobile-First Indexing niet noodzakelijk betekent dat Google geen websites meer zal crawlen met zijn desktop spider. Het zal dit blijven doen om de content van beide versies te vergelijken.
Ik heb het proces van crawlen en indexeren nu vanuit een theoretisch perspectief uitgelegd. Laten we nu even kijken welke stappen je zelf kunt ondernemen om dit proces te versnellen of verbeteren.
Het proces van crawlen en indexeren
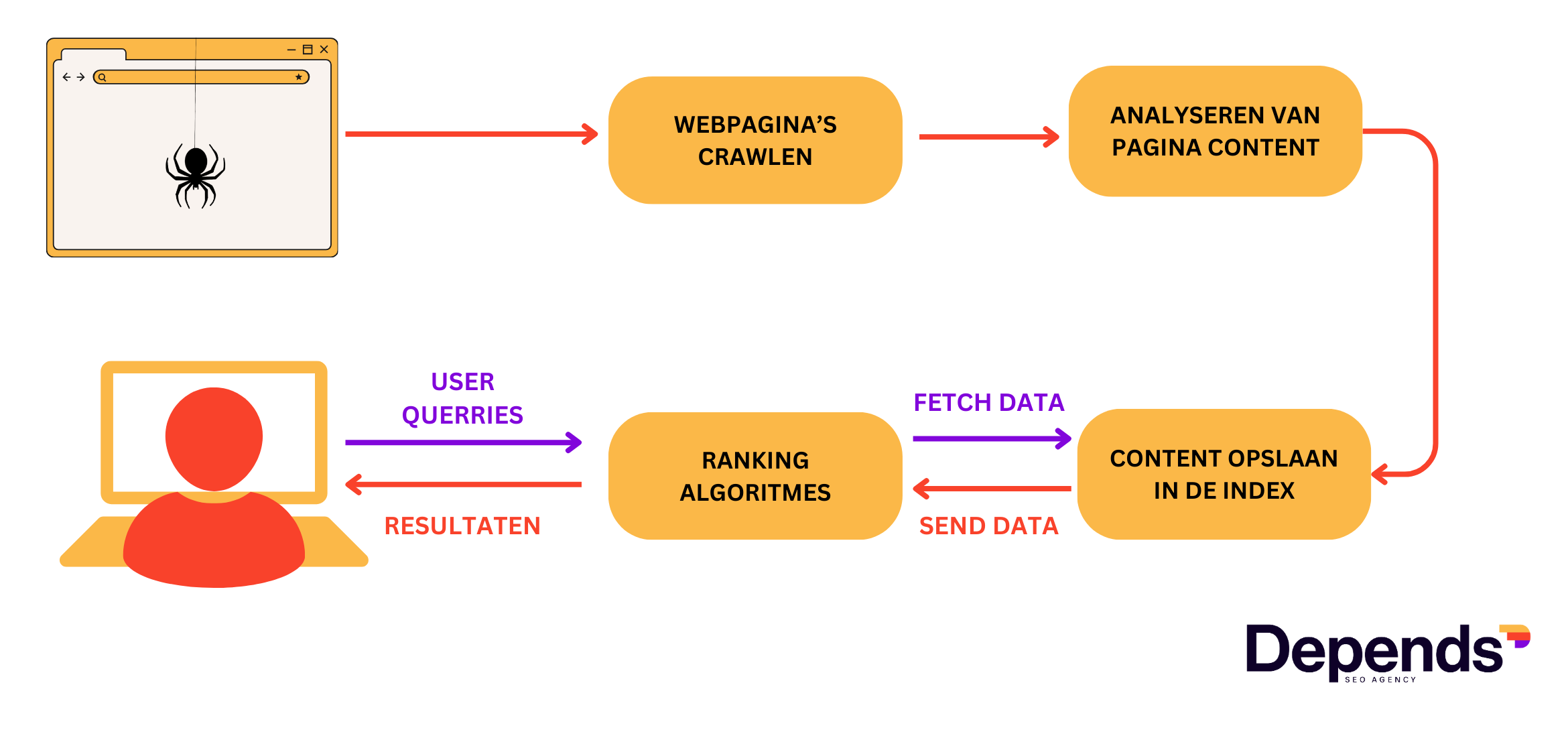
Hoe laat je Google een website crawlen en indexeren?
Er zijn verschillende manieren om het crawlen en indexeren te beïnvloeden.
1. Doe niets – de passieve aanpak
Eigenlijk hoef je helemaal niets te doen om je website te laten crawlen en indexeren. Het enige wat je nodig hebt is één link van een externe website en GoogleBot zal uiteindelijk alle beschikbare pagina’s gaan crawlen en indexeren.
Kies je voor deze aanpak, dan kan het crawlen en indexeren van je pagina’s vertraging oplopen. Het kan namelijk enige tijd kan duren voordat een webcrawler je website ontdekt.
2. Pagina’s indienen in het URL-inspectietool van Search Console
Een van de manieren waarop je het crawl en indexatie proces kunt versnellen van een webpagina is door deze in te dienen in het URL-inspectietool van Google Search Console. Op die manier vraag je rechtstreeks aan Google om een bepaalde pagina (opnieuw) te indexeren.
Dit tool is handig als je een gloednieuwe pagina hebt of als je substantiële wijzigingen hebt aangebracht aan bestaande pagina’s en je die vervolgens zo snel mogelijk wilt laten indexeren.
Het proces is redelijk simpel:
- Ga naar Google Search Console en voeg een URL toe aan de zoekbalk bovenaan. Klik op Enter.
- Google Search Console zal nu de status tonen van de pagina. Als deze nog niet geïndexeerd is kun je hiervoor een aanvraag indienen.
- Het URL-inspectietool begint te testen of de live versie van de URL kan worden geïndexeerd (dit kan een paar seconden of minuten duren).
- Van zodra het testen met succes is voltooid, verschijnt er een melding die bevestigt dat de URL is opgenomen in de crawl wachtrij ter indexatie. Het indexering proces kan enkele minuten tot meerdere dagen duren.
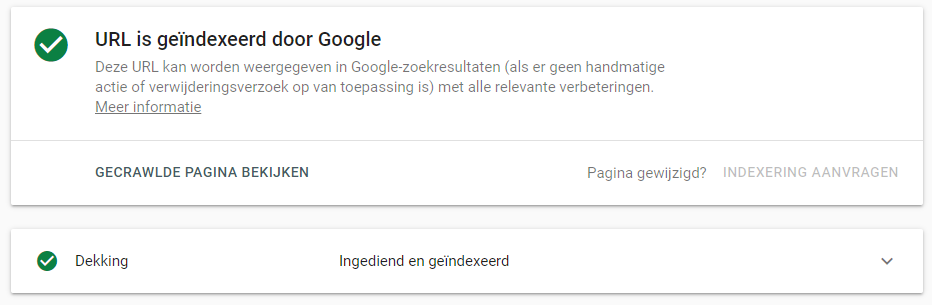
Via de URL inspectietool in Google Search Console kun je een pagina laten crawlen en indexeren in Google.
3. Dien een XML sitemap in
Een XML sitemap is een overzicht van de structuur van je website, met alle pagina’s erin die je wil laten indexeren door Google.
Het belangrijkste voordeel van een sitemap is dat het voor een zoekmachine veel gemakkelijker wordt om je website te crawlen. Je kunt een groot aantal URLs tegelijk indienen en zo het algehele indexering proces van je website versnellen.
Google op de hoogte brengen van je sitemap doe je opnieuw in Search Console:
- Ga naar Google Search Console.
- Klik op sitemaps.
- Voeg je nieuwe sitemap toe en klik vervolgens op verzenden.
Na het indienen van de sitemap zal Google de sitemap bekijken en elke pagina crawlen.
4. Goede interne links
Een sterke interne linkstructuur kan wonderen doen voor de indexatie van een website. Hoe doe je dat? Kies voor een platte website structuur waarbij alle pagina’s minder dan drie kliks van elkaar verwijderd zijn:

Interne links zijn heel belangrijk voor grote webshops, en websites die duizenden pagina’s bevatten. Zo kan, bijvoorbeeld, het optimaliseren van je interne linkstructuur een echte gamechanger zijn als je bezig bent met e-commerce SEO.
Hoe voorkom je dat Google je pagina’s crawlt en indexeert?
Er zijn verschillende redenen waarom je bepaalde content niet wil laten indexeren door zoekmachines. Bijvoorbeeld:
- Privé content (persoonlijke gegevens van gebruikers)
- Duplicate content (pagina’s die identiek dezelfde inhoud bevatten)
- Leg of error pagina’s (work-in-progress pagina’s die nog geen meerwaarde hebben)
Laat ons eens kijken naar onze opties als het gaat om het voorkomen van crawlen en / of indexeren.
1. Gebruik robots.txt (om crawlen te voorkomen)
Een robots.txt bestand is een tekstbestand met directe opdrachten voor crawlers. Telkens wanneer crawlers een website bezoeken, controlleren ze eerste of er een robots.txt aanwezig is en wat de instructies zijn. Nadat ze de commando’s uit het bestand gelezen hebben, beginnen ze met het crawlen van je website.
Door “allow” en “disallow” richtlijnen in het bestand te gebruiken, kun je webcrawlers vertellen welke delen van de site moeten bezocht en gecrawld worden en welke pagina’s met rust gelaten moeten worden.
Je kunt er voor kiezen om duplicate content pagina’s, privé pagina’s, pagina’s met een parameters in de URL structuur, thin content en test pagina’s niet te laten crawlen door middel van een “disallow”. Zonder deze instructie zal een crawler deze pagina’s wél crawlen.
Hoewel de robots.txt file een goede manier kan zijn om te voorkomen dat de GoogleBot je pagina’s crawlt, moet je deze methode niet gebruiken om content te verbergen. Disallowed pagina’s kunnen nog altijd worden geïndexeerd als andere websites naar deze URLs verwijzen.
Om te voorkomen dat pagina’s worden geïndexeerd, is er een andere, efficiëntere methode: de Robots Meta Directives.
2. Gebruik het “noindex” signaal (om indexatie te voorkomen)
De robot meta directives zijn kleine stukjes HTML-code die je in het gedeelte van een webpagina plaatst en die zoekmachines vervolgens instrueren hoe ze een pagina moeten crawlen en indexeren.
De meest voorkomende robots meta tag is de “noindex”. Deze tag wordt gebruikt om de zoekmachines aan te geven of je een bepaalde pagina wel of niet wilt laten indexeren.
Verder wordt een “noindex” tag ook vaak gebruikt om duplicate content te voorkomen of om websites die gedeeltelijk in ontwikkeling zijn nog niet te laten indexeren. Dit laatste is tevens ook een veel voorkomende fout wanneer webdevelopers een website of een gedeelte ervan opleveren. Er word dan vergeten de robots meta tag te verwijderen waardoor de site of het gedeelte ervan alsnog vindbaar is via een zoekmachine.
Een noindex tag ziet er zo uit:
Dit signaal is van toepassing op alle soorten webcrawlers. De noindex tag wordt meestal gecombineerd met de follow- of nofollow attributen om zoekmachines te vertellen of ze de links op de pagina moeten crawlen.
Gebruik nooit de noindex in combinatie met de robots.txt file.
Hoe zie je dat een pagina geïndexeerd is?
Als je wil nagaan of je pagina geïndexeerd is, dan heb je daar een paar verschillende opties voor.
1. Controleer het manueel
De eenvoudigste manier om te checken of je pagina geïndexeerd werd of niet, is door het site: commando te gebruiken.
Door site:depends.be in te geven, krijg je een overzicht van alle pagina’s die geïndexeerd zijn.
Wens je een specifieke pagina te zien (bijvoorbeeld de over ons pagina van Depends), pas je commando dan aan naar dit: site:https://depends.be/over-ons/
2. Controleer de dekking status
Als je een gedetailleerd overzicht wenst te krijgen van je geïndexeerde pagina’s, dan kun je hiervoor terecht in Google Search Console, in het Dekking rapport.
3. Gebruik het URL-inspectietool
Het URL-inspectietool in Google Search Console kan informatie verschaffen over individuele pagina’s van een website vanaf de laatste keer dat ze zijn gecrawld. Je kunt controleren of je pagina:
- problemen heeft ;
- werd gecrawld en wanneer de laatste keer was;
- is geïndexeerd en kan worden weergegeven in de zoekresultaten.


